






随着大数据时代的到来,聚类分析作为一种无监督学习方法,广泛应用于数据挖掘、图像识别、社交网络分析等领域,DBSCAN(Density-Based Spatial Clustering of Applications with Noise)作为一种基于密度的聚类算法,由于其能够发现任意形状的簇并有效处理噪声点,受到了广泛关注,随着数据集的增大和复杂度的提升,DBSCAN算法的效率问题逐渐凸显,本文将探讨如何实现DBSCAN的高效版本,以应对大规模数据的挑战。
DBSCAN算法原理
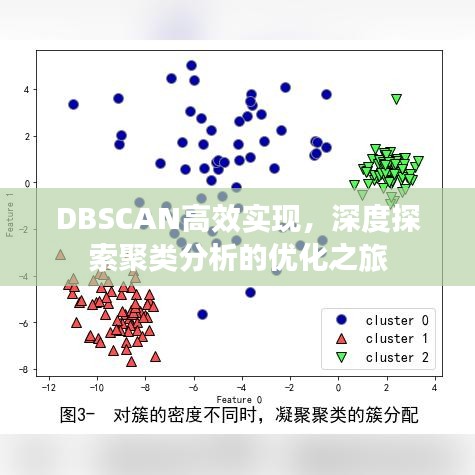
DBSCAN算法基于密度概念进行聚类,其基本思想是将数据点划分为核心点、边界点和噪声点,核心点是指邻域内的点足够多的点;边界点是离核心点较近的点;噪声点则是远离所有簇的点,通过连接核心点和它们的邻居点形成聚类,这种算法能够发现任意形状的簇,并且不需要预设簇的数量,随着数据量的增长,DBSCAN算法的效率和性能面临挑战。
优化策略
为了提高DBSCAN算法的效率,可以从以下几个方面进行优化:
1、数据预处理:对输入数据进行预处理,如去重、归一化等,以减少计算量,利用数据降维技术(如PCA、LDA等)减少数据的维度,降低计算复杂度。
2、优化距离计算:距离计算是DBSCAN算法的核心部分,优化距离计算可以显著提高算法效率,利用空间索引技术(如KD树、R树等)优化邻近点的搜索过程,减少不必要的距离计算。
3、并行化策略:利用并行计算技术,将DBSCAN算法的计算过程分配到多个处理器上并行执行,提高计算速度,利用GPU加速技术进一步提高计算效率。
4、参数优化:DBSCAN算法中的两个关键参数是邻域半径(eps)和最小点数(MinPts),合理选择这两个参数可以显著提高算法的效率,通过动态调整参数或使用智能参数选择方法,可以在不同数据集上实现更好的性能。
高效实现方法
基于上述优化策略,我们可以实现DBSCAN的高效版本,具体实现方法如下:
1、数据预处理:对输入数据进行去重、归一化等预处理操作,并利用数据降维技术减少数据的维度。
2、构建空间索引:利用KD树或R树等空间索引技术构建数据索引,优化邻近点的搜索过程。
3、并行计算:将DBSCAN算法的计算过程分配到多个处理器上并行执行,提高计算速度。
4、智能参数选择:通过动态调整邻域半径和最小点数等参数,或在数据集上采用智能参数选择方法,以提高算法的效率。

本文探讨了DBSCAN高效实现的方法,包括数据预处理、优化距离计算、并行化策略和参数优化等方面,通过采用这些优化策略和方法,可以显著提高DBSCAN算法的效率,使其在大规模数据上表现出更好的性能,随着大数据和人工智能技术的不断发展,DBSCAN算法的应用场景将更加广泛,对其高效实现的研究将具有更重要的意义,未来研究方向包括进一步优化算法性能、提高算法的鲁棒性和可扩展性等方面。
转载请注明来自上海伊滨办公家具有限公司,本文标题:《DBSCAN高效实现,深度探索聚类分析的优化之旅》




 沪ICP备16043738号-1
沪ICP备16043738号-1
还没有评论,来说两句吧...